
Klerk is a Kotlin framework designed to simplify backend data management by combining the database and business-logic layers, giving you a solid foundation to build your application upon. It helps you build secure systems that are easy to understand, avoid complexity, have fewer bugs, and low latency.
Klerk is open-source under the AGPL licence, with commercial licenses available.
Klerk means 'bookkeeper' in swedish.
Klerk is still in beta. The API is not yet stable. Some of the plugins are still in alpha.
Basic ideas
Klerk is built with the following principles:
Secure
Secure by design: All data interactions go through Klerk, ensuring that all authorization rules are enforced. This design prevents developers from accidentally bypassing security checks. If a developer needs to override a rule, they must explicitly state it, making such exceptions stand out in the code.
Secure by default: All data interaction is denied unless explicitly permitted. For any action to be allowed, there must be a rule that grants permission and no rule that denies it.
Audit trail: Klerk provides a built-in meaningful audit trail, recording not just data modifications but also data access, enhancing traceability and security.
Easy to understand
Klerk divides development into two levels: the higher (design) level and the lower (details) level. At the higher level, you design the system by defining its components. At the lower level, you describe each component in detail. This separation helps you maintain a clear overview of the system, making it easier for others to understand and collaborate. Additionally, Klerk can generate state diagrams and documentation, even before the lower-level implementation begins.
It is possible (and encouraged) to start with the higher level and use the generated documentation to get the design approved by all stakeholders before writing any code on the lower level.
Avoids complexity
Klerk reduces the system's complexity in two ways: it takes care of the unavoidable complexities, and it forces you to write simple code. You primarily write pure functions and simple data structures, avoiding complicated abstractions, inheritance, or dependencies that can entangle your system.
Even if your system grows large, it remains understandable because it's composed of simple, independent parts. You can focus on one part without needing to understand the entire system, and you can modify one part without affecting others.
One of the main sources of complexity in information systems is state management. Klerk helps manage this complexity through state machines.
Fewer bugs
Klerk’s declarative approach reduces the likelihood of bugs. Since Klerk handles most of the infrastructure, you don’t have to worry about challenging issues like cache invalidation or race conditions. Klerk’s design also includes several features to help minimize bugs:
Consistency: Klerk analyzes your design at startup, detecting inconsistencies early. It also verifies that your data aligns with the design.
Explicit: Klerk requires explicit validation rules, reducing the chances of mistakes.
Keep the knowledge in one place: In traditional systems, both the backend and frontend must implement the same rules. With Klerk, the frontend can query the backend for these rules, ensuring consistency. For example, you can tell Klerk to generate a button or form for each possible action given the current state. If you don't like the button/form, you can render it yourself after asking Klerk if the action is possible given the current state.
Easy to test: Klerk forces you to write simple pieces of code, making it easier to write effective unit tests.
Low latency
End users are annoyed when a system is not responding quickly to user actions. In e-commerce, latency can even impact revenue. Klerk responds very quickly to requests, enabling developers to build software to be proud of.
What can you build with Klerk?
You are free to use other backend components to build whatever you want on top of Klerk, such as
- Web applications using server-generated HTML
- APIs (JSON, REST, GraphQL) for your frontend
- Microservices communicating via RPC or message queues
Klerk excels when your business logic can be described as domain events (e.g. "the invoice has been approved") and when many of your business rules depend on state (e.g. "the invoice must be approved before it can be paid").
However, Klerk is not always the right choice. For trivial applications, the benefits of Klerk may not justify the learning curve. Klerk also has some limitations:
-
Klerk must currently run on a single machine. This means that it is not possible to have software redundancy to protect against hardware failures. It also means that Klerk is not horizontal scalable, which limits the system to a few thousand read requests per second on a fairly low-end server. There are plans to make Klerk run on multiple instances which will ensure high-availability and scaling.
-
Klerk is not designed to handle many thousands of commands (mutations) per second, but it can sustain over 100 commands per second.
-
Klerk processes all data at startup, among other things to make sure the configuration (your code) is compatible with all data. As a consequence, the upstart time may be noticeable if you have many millions of entities in the system.
For systems expecting millions of concurrent users, Klerk may not be ideal unless you can partition the data (e.g., in single-tenant systems).
Core concepts
Declarative
A traditional system is built so that it (hopefully) behaves according to the specification. With Klerk it is the other way around: you give the specification to Klerk in a semi-declarative format and Klerk enforces data integrity according to the rules you define. These rules include:
- Data types
- Validation
- Allowed events based on data state
- How events modify data
- Authorization for triggering events
- Data access permissions
- And more
You declare all this using code. As you may know, Kotlin lends itself to making this kind of domain-specific language (DSL). The DSL is used to describe the system on the higher level. When it comes to the details, normal Kotlin code is used.
Since Klerk understands the specification, it can be queried for both data and rules. This is particularly useful when building UIs. For example, Klerk can tell you whether a "Send invite" button should be visible, what fields a form should include, and what the validation rules are. You can even submit a dry-run command to see what would happen without actually performing the action.
This approach keeps your business logic and UI in sync. It is even possible to build an auto-generated UI that is updated as soon as you change the business logic. In fact, Klerk comes with a built-in auto-generated admin UI.
Other tools also take advantage of this queryable configuration. There is an auto-generated GraphQL API. Klerk also ships with a form builder that generates HTML forms based on your data and rules.
The ability to query rules also opens up new possibilities for system documentation. Klerk can generate state diagrams, helping non-programmers understand system behavior. Having an up-to-date, accessible and understandable documentation is useful for many stakeholders (product owners, customers, testers, onboarding developers, support, sales). Here is an example of a state diagram for a chess game:
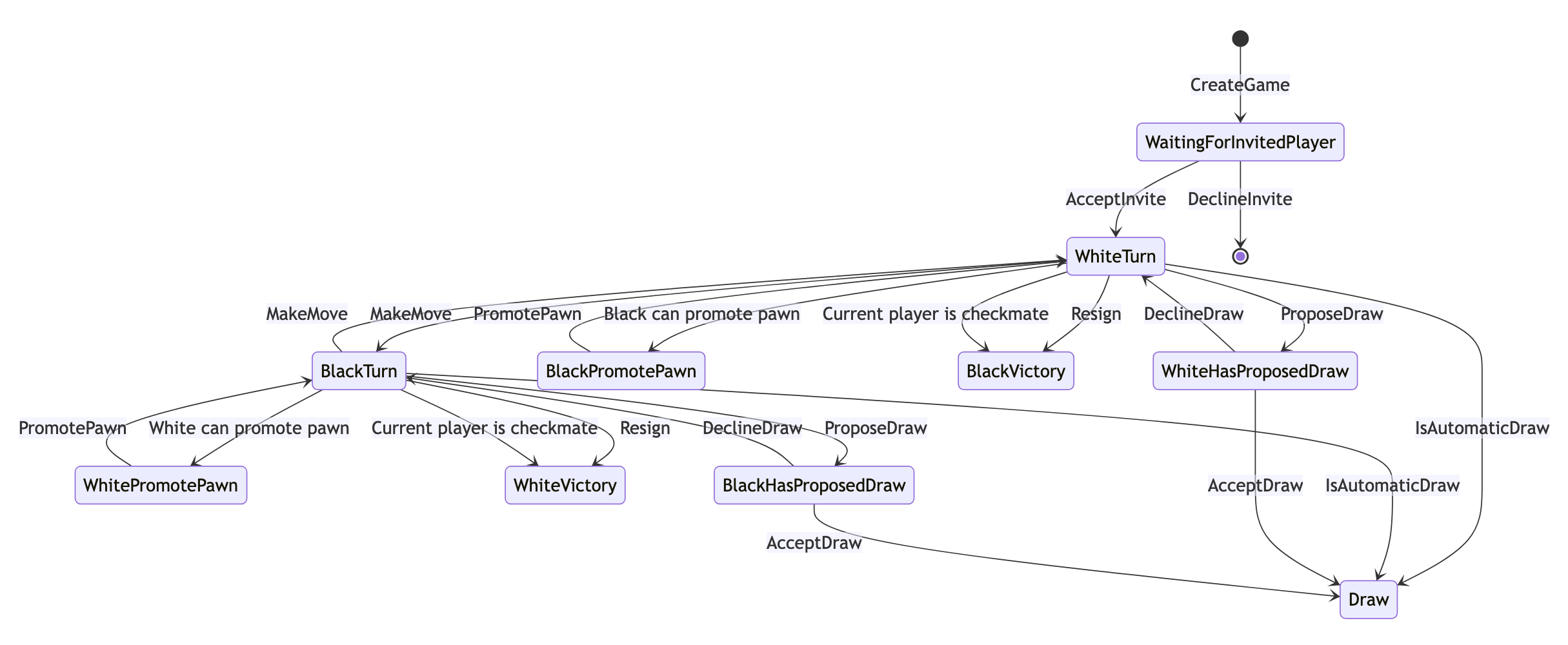
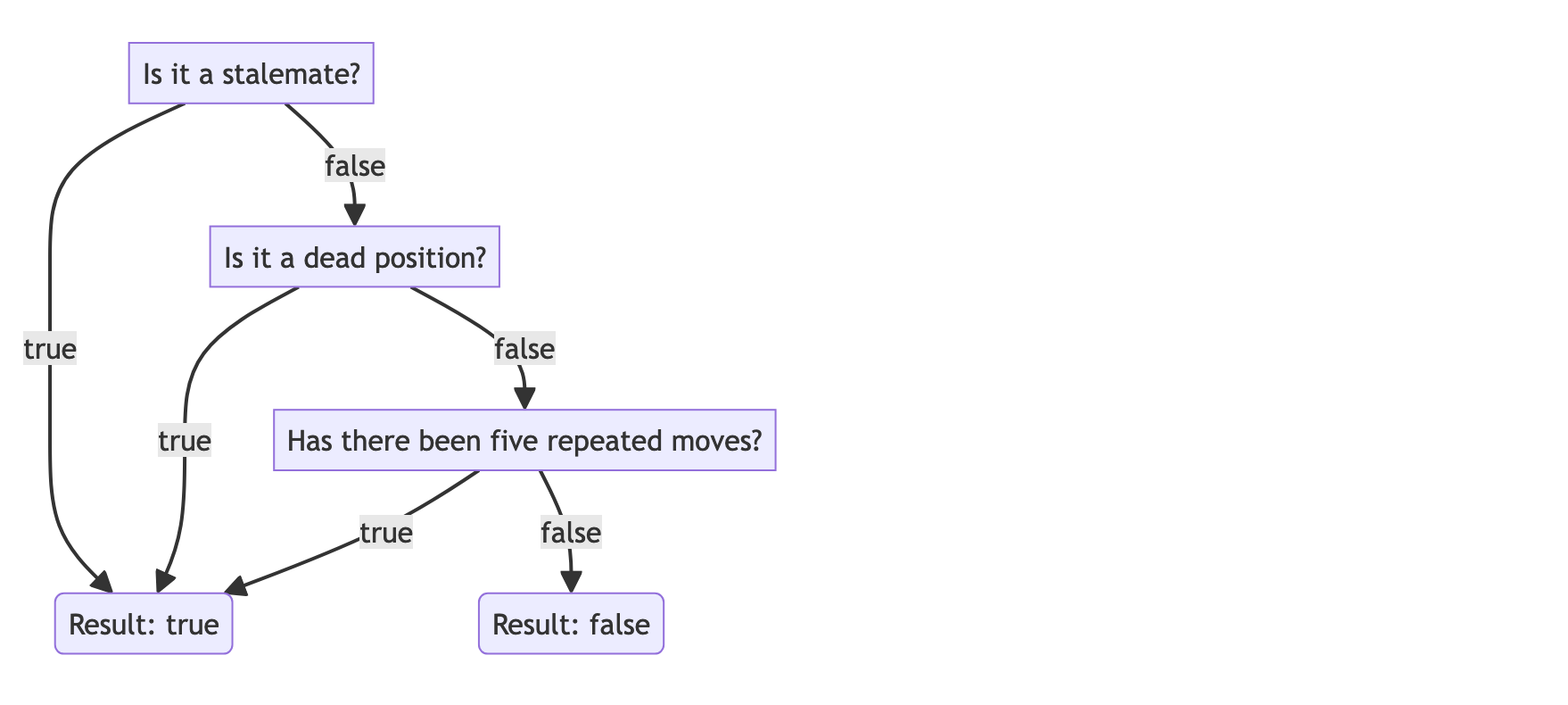
In this state diagram, there is a line with a label "IsAutomaticDraw". There is a simple algorithm determining whether this state transition should happen or not, this algorithm can also be visualized:
Event driven
Data is modified by sending commands to the framework, which may result in one or more domain events.
For example, if you want to update the favoriteBook property on a
User model, you will not execute an SQL update command like with most databases. Instead, you configure the
system
to accept an event called SetFavouriteBook, define on which type of
model and state the event applies. You also specify its parameters and rules for validation and authorization.
You then write a function to handle how the event updates the model.
Each model in Klerk has its own state machine. You declare the model’s states, define which events are accepted in each state, and specify what happens when an event is triggered.
Learn more
Check out the example projects and read the documentation to get started.